Over the last year, I have spent a lot of time experimenting with AI across different parts of software delivery. Like many engineers, I started with coding assistants. I asked AI to generate APIs, classes, unit tests, database queries, and documentation. The results were often impressive. Features that might have taken hours to implement manually could be produced in minutes. The code compiled, the tests passed, and the overall structure looked surprisingly professional. It was easy to understand why so many teams quickly embraced these tools.
As the technology improved, I started pushing the experiment further. Instead of using AI only for coding, I began using it for requirements analysis, user stories, acceptance criteria, architecture discussions, test planning, deployment configurations, and technical documentation. Once again, the results were impressive. AI was able to produce artifacts that looked very similar to what an experienced software professional might create. User stories followed standard templates. Architecture diagrams looked clean and organized. Test cases appeared comprehensive. Documentation was clear and easy to read.
At first, this felt like a massive productivity breakthrough. Then I noticed something interesting. The generated artifacts often looked better than they actually were. Requirements appeared complete while missing important business rules. Architecture diagrams looked elegant while ignoring operational realities. Test plans contained dozens of scenarios but overlooked the risks most likely to cause production incidents. The problem was not that the outputs were obviously wrong. The problem was that they were convincing.
That observation gradually changed the way I think about reviews. Many teams today review AI-generated work using the same approach they use for human-generated work. In my experience, that is becoming increasingly ineffective. The nature of review itself is changing. When reviewing work created by another engineer, we are usually looking for mistakes. When reviewing work created by AI, we are often looking for assumptions. Those are not the same activity.
How We Review Human Work
When we review something produced by another person, we implicitly assume that the author has made conscious decisions. An analyst may have spoken with business stakeholders. An architect may have evaluated multiple alternatives before selecting a particular design. A developer may have chosen one implementation approach over another after considering performance, maintainability, and risk. Even when people make mistakes, there is usually a chain of reasoning behind the artifact.
Human-generated work also tends to reveal uncertainty. Requirements documents often contain open questions. Design documents may identify unresolved decisions. Developers frequently leave comments, notes, or TODOs indicating areas where additional clarification is required. During code reviews, it is common to hear phrases such as "I was not sure about this requirement" or "I could not find any information about this edge case." These signals help reviewers focus their attention on areas that deserve deeper investigation.
AI-generated work behaves very differently. Modern AI systems rarely expose uncertainty. Instead, they attempt to complete the task using whatever information is available. If important context is missing, the system usually generates something plausible enough to fill the gap. Sometimes those assumptions happen to be correct. Sometimes they are not. The challenge is that both outcomes often look equally convincing. As a result, reviewers can no longer rely on the same signals they have used for years when reviewing human work.
AI Optimizes for Plausibility, Not Correctness
One of the most important things to understand about AI-generated work is that it is optimized to produce outputs that look reasonable. In many situations, this is exactly what we want. A requirement should be readable. A design should be coherent. A piece of code should follow established conventions. However, there is an important difference between something that looks reasonable and something that is actually correct for a particular context.
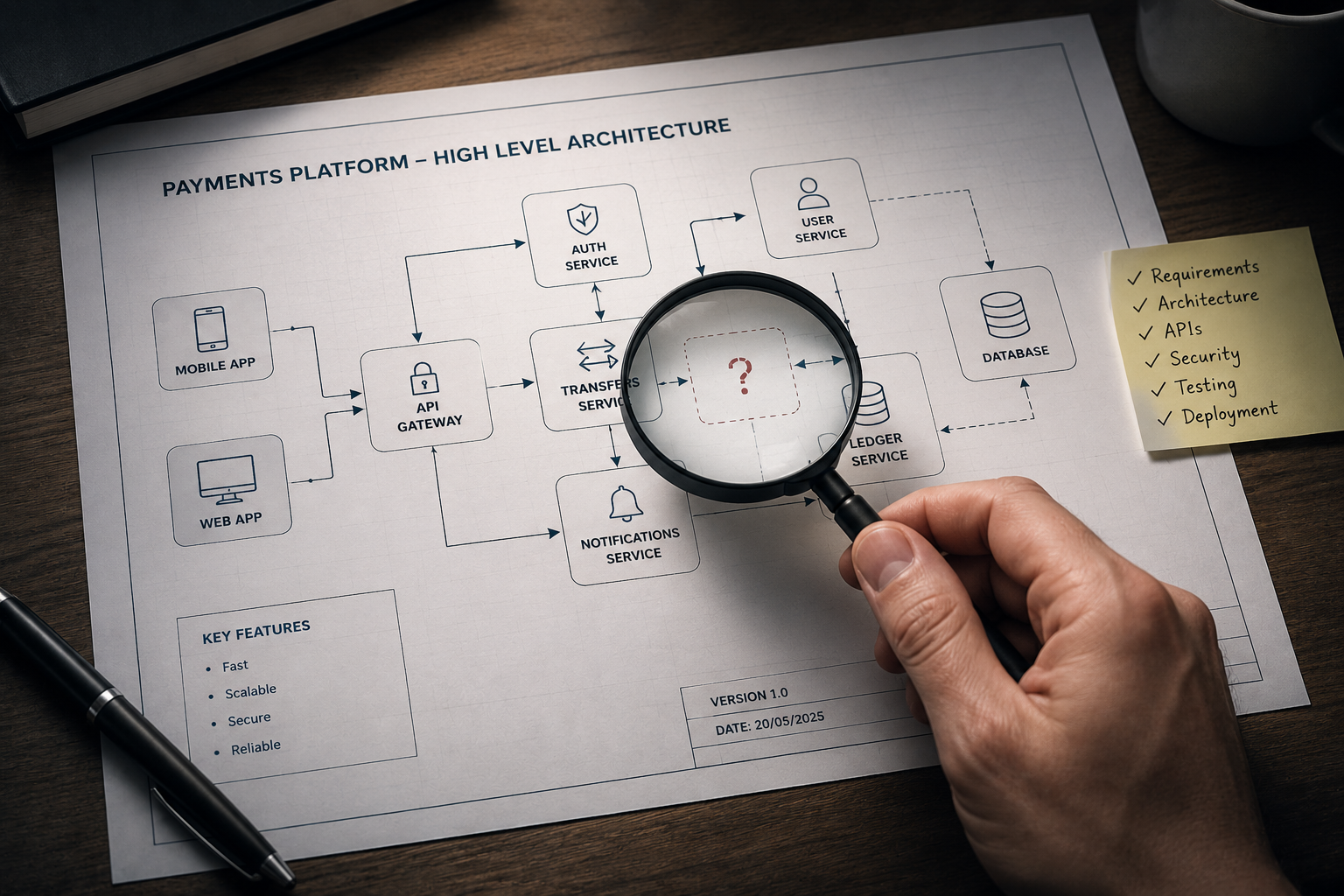
Imagine asking an AI assistant to propose a high-level architecture for a funds transfer system. The resulting diagram might show a mobile application communicating with a transfer service, which in turn stores data in a database. The architecture looks clean and understandable. If the goal is to explain the basic flow of a transfer, the diagram appears perfectly acceptable.
An experienced architect, however, immediately sees a different picture. Real-world transfer systems rarely consist of only three components. There may be fraud detection services, audit systems, transaction limit engines, notification services, monitoring infrastructure, compliance checks, and integration points with external payment networks. None of these omissions make the AI-generated architecture look wrong. In fact, the diagram may still appear elegant and professional. The issue is that it represents a generic solution rather than the specific solution required by the business context.
This is why reviewing AI-generated artifacts requires a different mindset. Instead of asking whether something looks sensible, we must ask whether it is appropriate for the specific environment in which it will operate. Plausibility is often easy to achieve. Correctness is much harder.
AI Hides Missing Context
The second pattern I frequently encounter is that AI tends to hide the absence of context. This is perhaps the biggest difference between reviewing AI-generated work and reviewing human-generated work.
Consider a simple requirement for transferring funds between bank accounts. If a human analyst receives incomplete information, they will often respond by asking questions. They may want clarification about transfer limits, beneficiary management, approval workflows, fraud controls, or regulatory requirements. The gaps in understanding become visible because the analyst explicitly identifies them.
AI behaves differently. If the prompt simply asks for a funds transfer requirement, the assistant will usually generate a polished and complete-looking artifact. The resulting document may contain a user story, acceptance criteria, and several business rules. To a casual reader, the requirement appears comprehensive.
The problem is that AI cannot include information it was never given. If the prompt did not mention fraud screening, transaction limits, compliance checks, or operational constraints, those topics may simply disappear from the generated requirement. The document still looks complete because the writing quality is high. The missing context is hidden behind a professional presentation.
This creates a new responsibility for reviewers. Instead of only searching for errors, they must actively search for missing information. One of the most useful questions a reviewer can ask when examining AI-generated work is: "What context might have been unavailable when this artifact was created?" That question often reveals risks that are invisible during a traditional review.
Why Polished Output Can Be Dangerous
One reason AI-generated work can be difficult to review is that it often looks better than the average first draft produced by a human. Requirements are neatly organized. Documentation is well structured. Code follows naming conventions. Test cases are presented in a consistent format. The overall quality of presentation creates an impression of competence.
Unfortunately, presentation quality and engineering quality are not the same thing.
I have seen AI-generated test plans containing dozens of scenarios while completely missing resilience testing. I have seen architecture proposals that described functional components in great detail while ignoring operational concerns such as observability and disaster recovery. I have seen code that passed every unit test while containing performance problems that would become obvious only under production load.
The common factor in all of these examples is that the artifacts looked finished. Because they looked finished, reviewers naturally lowered their guard. Human beings are wired to associate professional presentation with quality. AI exploits that tendency unintentionally by producing outputs that are often polished regardless of whether the underlying reasoning is complete.
For this reason, one of the most valuable habits reviewers can develop is learning to separate presentation quality from solution quality. A beautifully written requirement can still be incomplete. A well-documented design can still be flawed. A clean codebase can still contain serious defects. The appearance of completeness should never be mistaken for actual completeness.
Reviewing Different Types of AI-Generated Artifacts
These patterns become visible throughout the software delivery lifecycle. Requirements may appear complete while hiding missing business constraints. Acceptance criteria may focus heavily on happy-path scenarios while ignoring failures and edge cases. Architecture proposals may describe functional behavior without adequately considering scalability, security, operational support, or resilience. Test cases may provide broad coverage of expected behavior while overlooking the scenarios most likely to cause production incidents.
The same pattern continues into implementation. AI-generated code often follows best practices and looks highly maintainable. At the same time, it may contain performance bottlenecks, security vulnerabilities, scalability limitations, or subtle misunderstandings of business rules. Infrastructure configurations frequently work perfectly in development environments but omit considerations such as high availability, autoscaling, disaster recovery, and operational monitoring. Documentation may read like it was written by a professional technical writer while failing to explain important operational limitations or failure scenarios.
The specific artifacts change, but the review challenge remains remarkably consistent. The reviewer must identify assumptions, missing context, hidden constraints, and unstated risks. This requires a different kind of attention than traditional defect hunting.
Sometimes the Review Should Start Earlier
Throughout this article, we have focused on reviewing AI-generated outputs. Requirements, architecture, tests, code, infrastructure configurations, and documentation all require careful validation before they can be trusted. However, as AI becomes more integrated into software delivery, I believe some teams will increasingly review the inputs as well.
In traditional software engineering, poor outputs are often traced back to poor inputs. Ambiguous requirements produce incorrect implementations. Incomplete designs produce fragile systems. The same principle applies to AI-assisted development. If an assistant receives incomplete context, unclear instructions, or insufficient business information, the resulting artifacts will often reflect those limitations.
This observation connects to something I explored in earlier articles. Repository structure, architectural documentation, coding standards, user stories, acceptance criteria, and operational knowledge all serve as context for AI systems. When that context is incomplete or poorly organized, the generated outputs become less reliable. In many cases, defects discovered during review are not actually caused by the AI. They are symptoms of missing context that existed long before generation began.
Interestingly, some organizations building AI-powered products have already started treating prompts, instructions, and context packages as engineering artifacts. They version them, test them, and manage their evolution over time. I suspect similar practices will gradually emerge in software engineering teams. While most organizations today focus on reviewing AI outputs, mature teams may eventually review both the outputs and the inputs that shape them.
The New Skill Software Engineers Need
For decades, software engineering has placed enormous value on the ability to create artifacts. We learned how to write requirements, design systems, implement code, produce tests, and create documentation. These skills remain important, but AI is rapidly reducing the effort required to produce the first version of many of these outputs.
As creation becomes easier, evaluation becomes more valuable.
The engineers who thrive in an AI-assisted world may not be the people who generate the most artifacts. They may be the people who can most effectively validate those artifacts. They will know how to identify hidden assumptions, uncover missing context, challenge plausible-looking solutions, and recognize risks that are invisible to less experienced reviewers.
In many ways, this is not a completely new skill. Experienced architects, technical leads, business analysts, and engineering managers have been performing this type of thinking for years. What is changing is the leverage. When AI can generate large amounts of work very quickly, the quality of review becomes one of the primary factors determining the quality of the final system.
Final Thoughts
Much of the conversation around AI in software engineering focuses on generation. We discuss generating code, generating tests, generating documentation, generating user stories, and generating designs. These are important capabilities, and they will continue to improve. However, the more interesting question may not be what AI can generate. The more interesting question is how we evaluate what it generates.
Human review is not becoming less important in the age of AI. If anything, it is becoming more important. The focus of review is simply shifting. We are spending less time looking for obvious mistakes and more time examining assumptions. We are spending less time checking formatting and more time searching for missing context. We are spending less time asking whether an artifact looks professional and more time asking whether it is truly correct for the problem at hand.
AI is making artifact creation faster. Human judgment remains responsible for determining whether those artifacts deserve to be trusted. That is why reviewing AI-generated work is different, and why it may become one of the most important software engineering skills of the coming decade.